
Stale hidden states in PPO-LSTM
I’ve been using Proximal Policy Optimization (PPO, Schulman et al. 2017) to train agents to accomplish gridworld tasks. The neural net architectures I’ve been using include LSTM layers – this gives the agents the capacity to remember details from earlier in an episode when choosing actions later in the episode. This capacity is particularly important in partially observed environments that are ubiquitous in multi-agent reinforcement learning (MARL).
I’ve found PPO and LSTMs to be a potent combination, but getting it to work well has required lots of effort and attention to detail. In this post I’ll discuss hidden state refreshing, a feature of my implementation that I have found to be important for achieving good performance in partially observed environments with sparse rewards.
As a teaser, here’s a video of a solitary agent locating and navigating between four goals in a Marlgrid goal cycle environment. PPO-LSTM with hidden state refreshing has enabled me to train agents to accomplish this sort of challenging partially observed exploration tasks with just my desktop computer.
In on-policy deep reinforcement learning algorithms, agents alternate between collecting a batch of experience (storing it in a replay buffer) and updating their parameters based on that experience. Parameter updates that cause big changes in agent behavior policies are often harmful to performance. Algorithms like Trust Region Policy Optimization (TRPO, Schulman et al. 2015) and PPO offer ways to update agent parameters while keeping the induced policies within a “trust region” of the pre-update policies. In PPO (and particularly the PPO-Clip variant I’ve been working with), the policy network is trained with a surrogate objective that is maximized when the policy increases the likelihood of producing high-advantage actions without drifting too far from the pre-update policy.
Implementation details are important
RL Algorithms like PPO have lots of moving parts, and actually implementing them involves lots of small algorithmic design choices. Not all of these are considered core parts of the algorithm, but put together they can have a pretty big impact on performance. Engstrom et al. (2019) draw the striking conclusion that “much of PPO’s observed improvement in performance comes from seemingly small modifications to the core algorithm…” that had not been emphasized in published comparisons with other training methods.
Detail: early stopping
My implementation of PPO is based on the Spinning Up PPO code, from which it inherits lots of tweaks and good design choices. One of these is early stopping.
In PPO, Each batch update consists of several mini-batch gradient updates. This helps with sample efficiency, and the clipped surrogate objective helps prevent the updated policy from straying too far from the trust region. But as an extra guarantee, the mini-batch iteration terminates if the expected KL divergence between the current policy and the policy used to collect the experience exceeds some threshold (more on this later).
Detail: Hidden states
Adding a recurrent neural network like an LSTM to the policy and/or value networks gives an agent the capacity to use memory at the cost of significant implementation complexity. Much of this arises from the handling of hidden states.
PPO updates involves (1) computing policies and values for trajectories in the replay buffer, (2) using these to calculate losses for the policy and value networks, and (3) updating the networks’ parameters with stochastic gradient descent (typically Adam) to minimize these losses. SGD-style parameter updates typically work best when the loss is computed from uncorrelated samples rather than e.g. whole trajectories. In the specific context of on-policy RL, Andrychowicz et al. (2020) found that parameter updates that used multiple mini-batch gradient steps (with random transitions randomly assigned to mini-batches) were more effective than large-batch parameter updates that used the entire batch.
With architectures that include LSTMs, policies and values are functions of a hidden state as well as the observed state of the environment. Thus the loss for an arbitrary replay buffer transition depends on the hidden state associated with that transition. We cache hidden states alongside observed states/actions/rewards in the replay buffer to make sure we can compute losses efficiently.
Stale values in the PPO replay buffer
In off-policy RL, experience in the replay buffer can be re-used for a very large number of parameter updates. In the R2D2 paper, Kapturowski et al. (2019) showed that there are significant discrepancies between Q-values calculated with stale vs. fresh hidden states – “fresh” meaning recalculated with current (or recent) model parameters. The experience used for each parameter update in on-policy algorithms is collected with the most recent version of the policy and discarded after a single update, so the data used for each update (including saved hidden states) is less stale than with off-policy algorithms.
Even so, using fresh data for parameter updates can be important for on-policy reinforcement learning. In What matters in on-policy reinforcement learning?, Andrychowicz et al. (2020) argue that the advantage values used to estimate state values in on-policy reinforcement learning algorithms like PPO can become stale over the course of a single update. In typical implementations the advantages are computed using the value network only once per batch, but with each mini-batch iteration the stored advantages become less consistent with the current value network parameters. Andrychowicz et al. (2020) suggest mitigating this issue by recalculating advantages before each mini-batch iteration rather than before each batch update, and they show that this improves performance on their benchmarks.
The argument for refreshing advantages extends to hidden states for architectures with RNNs since as the hidden states saved in the buffer become more stale, using them to estimate quantities like advantage values will become less accurate.
Stale hidden states also potentially undermine the mechanisms used in PPO-clip to maintain trust regions during updates. During each minibatch policy update, current policies (calculated with the most recent network parameters) are compared to stored policies (that used with the pre-update parameters) for loss clipping. If the “current” policies are computed using stale hidden states, they might falsely appear more similar to the stored policies. This would get in the way of loss clipping from preventing large policy changes.
There is a similar issue with loss clipping: hidden states are needed to calculate the expected KL divergence between the pre-update and current policies when deciding whether to prematurely terminate an update step. If the hidden states are stale, then these estimates will be inaccurate, and early stopping will be less effective at keeping the policy within the trust region.
Fortunately since the replay buffers used for on-policy reinforcement learning are typically quite small (especially compared to those used in off-policy RL), it’s not too costly to simply recalculate the stored hidden states every few mini-batches. And if we are already following the recommendation of Andrychowicz et al. (2019) to periodically refresh advantages, then recalculating hidden states has a low marginal cost. So, I had the idea to apply the stale-state refreshing technique of R2D2 to PPO, and conducted some experiments to see how much it helped.
Experiments
I ran some experiments to test the impact of hidden state staleness on PPO performance in a couple different environments. In addition to policy performance, I computed the KL divergence of the pre- and post-update policies. In both cases I refreshed the hidden states before calculating the post-update policies for estimating the policy divergence.
The lines shown are means of 3 trials. The highlighted regions show +/-2 standard errors of the means.
Cluttered env
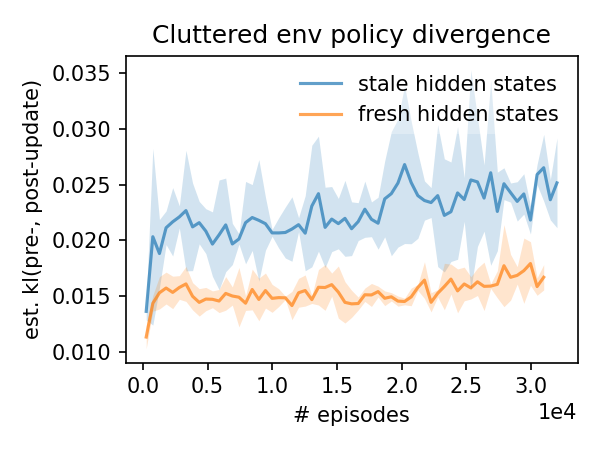
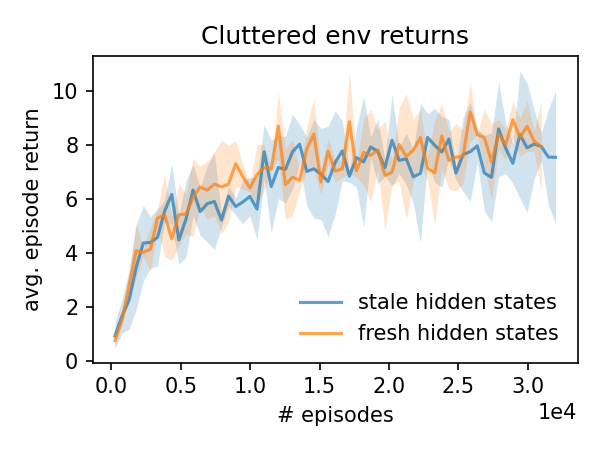
Without hidden state refreshing, updates cause much larger policy divergences. But this doesn’t impact performance all that much; the reward curves are pretty similar. This task isn’t too memory intensive; an agent with only feed-forward networks would probably do fine with a strategy like “move toward the goal if it’s visible, otherwise randomly move/rotate”.
Goal cycle env
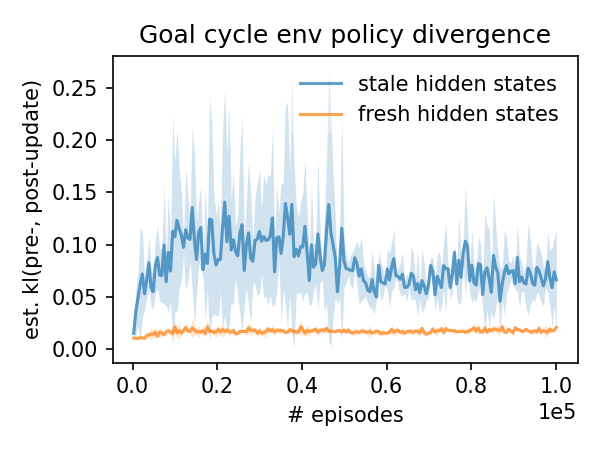
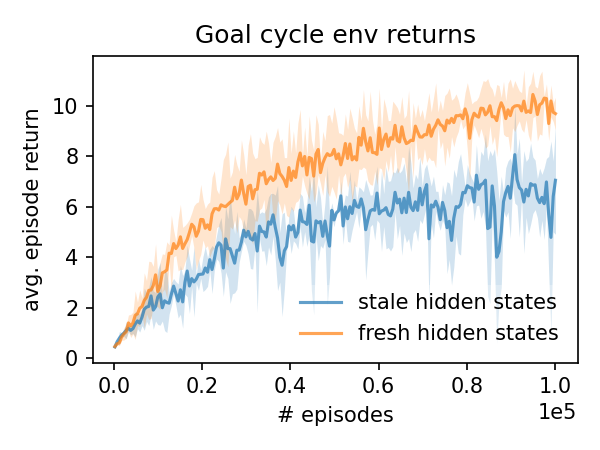
Hidden state refreshing makes a huge difference for goal cycle performance! When the hidden states are allowed to get stale, the combination of the PPO-Clip objective function and early stopping fails to keep the policies from changing dramatically during the updates – note that the y axis range is about an order of magnitude larger in the goal cycle divergence plot than the cluttered divergence plot. Because this task is more memory intensive, refreshing the hidden state is critical to achieving good performance.
References
John Schulman et al. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347, 2017.
John Schulman et al. Trust Region Policy Optimization. arXiv preprint arXiv:1502.05477, 2015.
Joshua Achiam. Spinning Up in Deep Reinforcement Learning. 2018.
Marcin Andrychowicz et al. What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study. arXiv preprint arXiv:2006.05990, 2020.
Logan Engstrom et al. Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO. arXiv preprint arXiv:2006.12729, 2020.
John Schulman et al. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv preprint arXiv:1506.02438, 2015.
Steven Kapturowski et al. Recurrent experience replay in distributed reinforcement learning. ICLR 2019.