
Social learning in goal navigation tasks
For the past few months I’ve been studying social learning in multi-agent reinforcement learning as part of the Spring 2020 OpenAI Scholars program. This is last in a series of posts I’ve written during the program, and in this post I’ll discuss some experiments I’ve been conducting to study social learning by independent RL agents. The first post in this series has lots of context about why I’m interested in multi-agent reinforcement learning. Before continuing I wanted to express my tremendous gratitude to OpenAI for organizing the Scholars program, and to my mentor Natasha Jaques for her incredible support and encouragement.
I spent much of the time dedicated to this project working on open-source tools to facilitate MARL research. I developed Marlgrid, a multi-agent gridworld environment (github, post), and a PPO-LSTM implementation (github, post) that I used to train agents. PPO is a powerful algorithm, and I recommend checking out the post I wrote about hidden state refreshing for details about how I got it working well with LSTMs for tasks that require memory (at desktop scale!).
Social learning in goal navigation tasks
Solitary humans are pretty useless, but they can gain pretty incredible capabilities through social interactions with other humans. By “capabilities” I don’t just mean personal capacity for thought, but rather all the ways an individual can interact with the world. For example, I can win a race with any non-human animal by tapping into a huge body of tools and cultural knowledge accumulated and accessed through social interaction with other humans. This is sort of an unfair comparison because I get to take advantage of human technology while other animals don’t, but that’s just the point: over time, interactions between individual humans have given rise to capabilities so great as to make direct comparisons with other animals almost nonsensical.
Independent multi-agent reinforcement learning
Understanding the ways AI systems might exhibit or benefit from social learning seems very important given how central it is to human intelligence. It seems likely that humans are biologically predisposed towards interacting with other humans, since infants show signs of cooperative social behavior like mimicry (Tomasello 2009) to a much greater degree than similar species (Henrich 2015). For this reason we might expect that AI systems might need to be endowed with inductive biases that encourage social learning in order to gain the capacity for skills-enhancing social learning.
Lots of work in multi-agent reinforcement learning is focused on building systems that perform well in multiplayer games (poker, go, Starcraft, Hanabi) or in finding ways to train agents that can coordinate effectively with other agents (cooperative games, autonomous vehicles). Developing mechanisms to encourage social learning would fall in this category. The objective in these applications is to develop capable systems, and many researchers reasonably use algorithms where agents have some sort of built-in bias to encourage the desired behavior – centralized critics, shared/cooperative/shaped rewards, etc. I’d characterize these research programs as offensive, in the sports sense.
But I’m particularly interested in the defensive program: identifying the circumstances in which social behavior might emerge on its own, without explicit encouragement. For starters, understanding the interactions that might arise between ostensibly independent agents seems like an obvious prerequisite for safely deploying adaptive systems. As reinforcement learning algorithms become more capable and widely deployed, it will be important to understand the circumstances in which collective behavior might arise – for instance, when automated stockbrokers might acquire knowledge or skills from one another.
Consider two experiments which both show the emergence of some phenomenon in a group of RL agents. In the first experiment, agents are given a reward or inductive bias that facilitated this phenomenon. In the second, independent agents exhibit the phenomenon without such encouragement. The first experiment lets us draw the conclusion that the particular methods/arrangement was sufficient for the phenomenon to emerge. If the phenomenon is “playing a strategy game without serious strategic weaknesses” or “successfully negotiating a traffic jam”, then this is really valuable. But the second experiment suggests a much stronger claim: the phenomenon is a property of the environment or scenario, and with smart enough agents we should expect to see it in any similar scenario.
Learning from experts
The purpose of this project is to identify circumstances in which novice agents can acquire skills through social learning.
With the perspective described above, this project is building towards determining when we might expect capable adaptive agents to learn from one another due to the structure of their environment, with the hope of drawing conclusions that are agnostic to the underlying RL algorithms. Thus, I’ll focus on independent multi-agent reinforcement learning, a context in which agents aren’t explicitly given a reason to cooperate.

This diagram illustrates the process of social learning: a novice learning in the presence of experts (solid line) is able to attain mastery of some skill. But if the novice is alone in the learning environment (dotted line), it is unable to obtain that skill and remains a novice. The human process of social learning fits this template. Humans are born with little innate skill. Individuals born outside human society are unable to develop the same capabilities as those that can profit from social learning and cultural knowledge. This pattern would hold for a wide variety of skill metrics such as vocabulary size, top speed, or twitter follower count.
Prior work
In Observational learning by reinforcement learning, Borsa et al. (2019) demonstrated that there are circumstances in which RL agents can learn more quickly and achieve higher rewards in the presence of experts. They examine two-agent scenarios in which a novice is trained by reinforcement learning (with A3C) in the presence of an expert agent that is hard-coded to perform the same task perfectly.
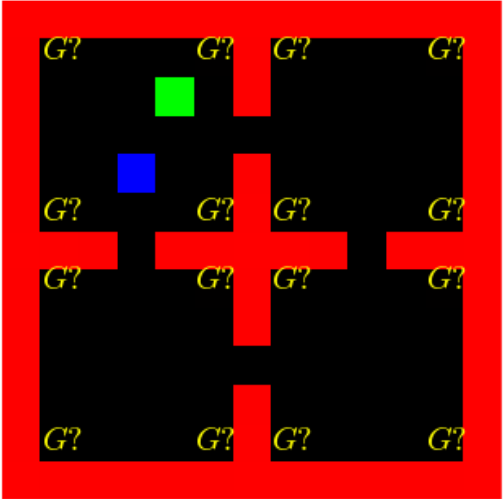
Among the scenarios they consider are exploratory navigation gridworld tasks where agents must locate and navigate to visually distinct target locations. As shown in the image and video above, both novices (green) and experts (blue) begin each episode in the top left portion of the map. The goal is placed randomly at one of the sixteen positions indicated by “G?”. Agents are rewarded for navigating to the purple goal tiles.
Borsa et al. found that in partially observed environments the presence of such hard-coded experts can ease learning for novices, but that the presence of experts didn’t improve the final skill of the trained novices.
Social skill acquisition
Learning environments
I have focused on exploratory navigation tasks in gridworld environments. With these tasks, expert agents are able to effectively locate and navigate to a certain objective. Such tasks are particularly promising for social learning because the skillful behavior required to achieve high rewards is visible to onlooking agents through the motion of experts.
Implementations of the environments I describe below are available in Marlgrid.
The “cluttered” environments (as shown in the video below) are exploratory navigation tasks that pose similar challenges to standard random maze tasks. The clutter in the environment can occlude agents’ views, and agents are unable to move through the clutter. Agents respawn randomly in the environment after reaching the goal, and continue doing so until the episode reaches a maximum duration.
Expert agents achieve high returns by quickly locating and navigating to the goal tile, and by storing appropriate information in their hidden states to hasten this process after each respawn (within a single episode). Novice agents accomplish this less quickly, and stand to achieve higher returns by using cues from the observed trajectories of expert agents to hasten their own search. But novices need to observe lots of expert behavior in order to learn from it, and novices in cluttered environments are somewhat unlikely to be close enough to experts to observe and learn from them.
I created the “goal cycle” environments to address this issue. In these environments, agents receive a reward of +1 for navigating between (typically three) goal tiles in a certain order, and receive a configurable penalty making mistakes. The size of the penalty relative to the reward determines the difficulty of exploration, and when the penalty is large the goal cycle becomes a hard-exploration task.
In the goal cycle environment, expert agents spend the first portion of each episode identifying the order in which to traverse the goals, and spend the rest of the episode collecting rewards by cycling between the goals in that order. Since novice agents very quickly learn to navigate to a first goal tile, encounters between novices and experts are much more likely than in the cluttered environment.
It is very difficult for novice agents to learn to identify the correct goal cycle when the penalty is large compared to the reward, since the penalty disincentivizes the sort of exploration that is necessary to discover the optimal strategy. Thus the size of the penalty gives a way to change the difficulty of learning by trial-and-error to directly solve the task relative to the difficulty of learning to accrue rewards through social behavior like following other agents.
In order to observe the sort of social learning described above, we need some way of training experts in environments with large penalties. We can do this by initially training the agents in a forgiving low-penalty environment then slowly increasing the penalty with a curriculum as shown here: 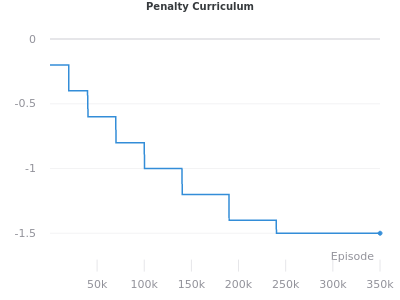
To expedite gathering experience in these environments, I used the SubprocVecEnv wrapper published in the with the OpenAI RL Baselines (P. Dhariwal et al. 2017) to collect experience in 8-64 parallel environments. Parallelized in this way, I am able to collect about a billion transitions of experience per day on a desktop computer, with agents calculating policies using the network architecture described below.
Algorithms
I’ve been training agents with Proximal Policy Optimization (Schulman et al. 2017). The neural networks expressing the policy and value functions share input layers as well as an LSTM. The network architecture is shown below.
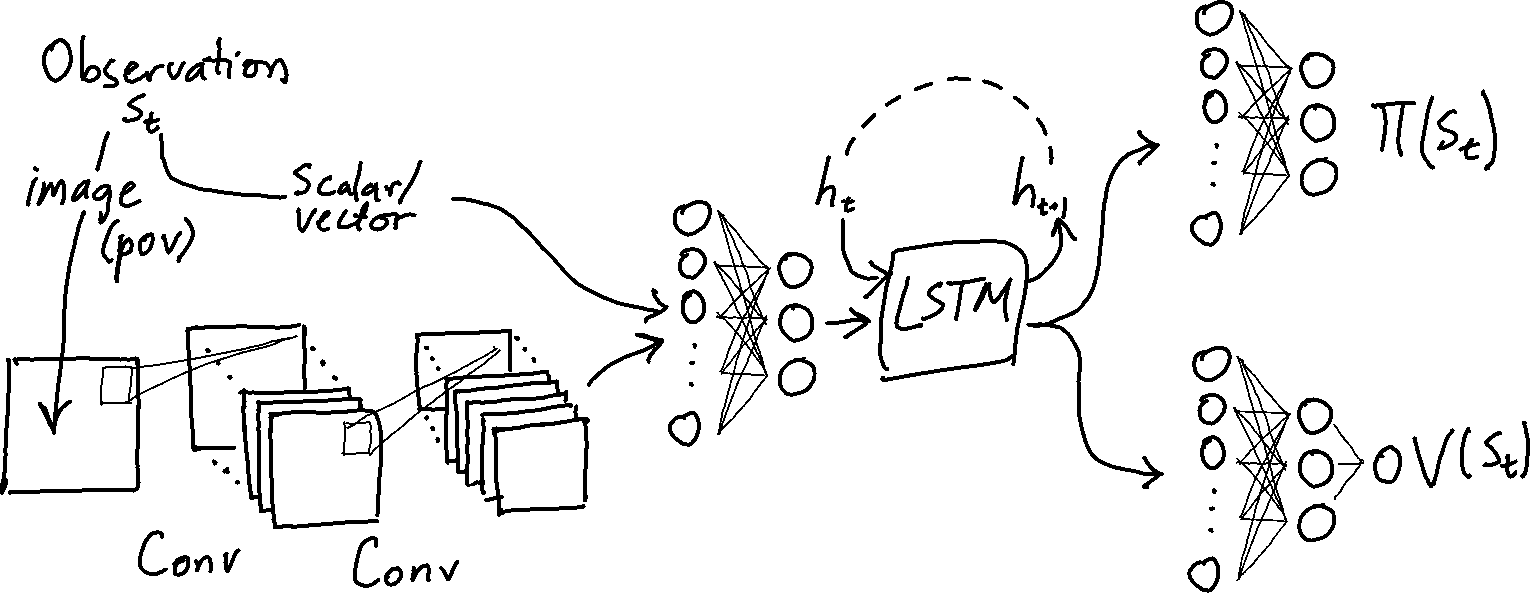
In the Marlgrid goal cycle environments, observations consist of images representing partial views and optionally include encoded scalar directional and positional information as well as the agent reward signal. The image is fed through series of convolutional layer then concatenated to the scalar inputs. This vector is fed through one or two fully connected trunk layers before the LSTM. The output of the LSTM is split and processed by separate MLP heads that output value estimates and policies.
As I described in another post, I found that periodically refreshing the hidden states stored in the agent replay buffers1 between mini-batch updates within a single gradient step to be crucial for good performance in tasks like goal cycle that require heavy use of memory over extended trajectories.
I implemented PPO-LSTM with hidden state refreshing using PyTorch. So that the parameter updates and hidden state updates are efficient, I implemented a custom LSTM layer that jit-compiles iteration over the items of the LSTM’s input sequence to expose an interface for tensors with dimensions
\[([ n_{seq}\times n_{mb}\times n_{in}], [n_{seq}\times n_{mb}\times n_{h}]) \rightarrow [n_{seq}\times n_{mb}\times n_{h}],\]where $n_{seq}$ is the sequence length, $n_{mb}$ is the mini-batch size, and $n_{h}$ is the size of the LSTM hidden state2. The PyTorch jit makes computing the full LSTM output for a full batch of episodes quite efficient. With 27x27 pixel input observations, a batch size of 32 and an LSTM hidden size of 256, it is possible to recalculate an entire batch worth of hidden states in a single forward pass. This takes well under 1GB of VRAM and is very fast, particularly since only a forward pass is needed and autograd can be disabled.
Experiments
Cluttered
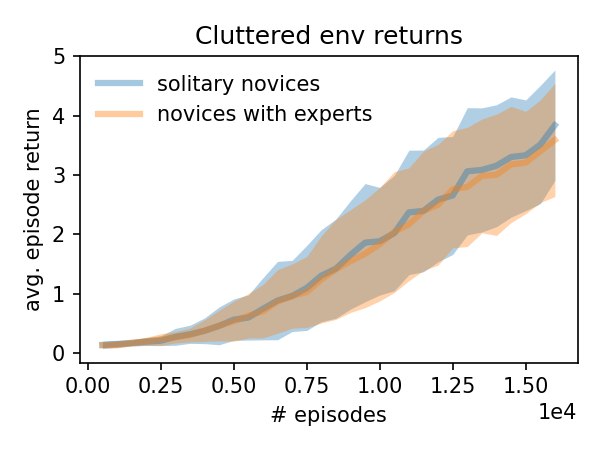
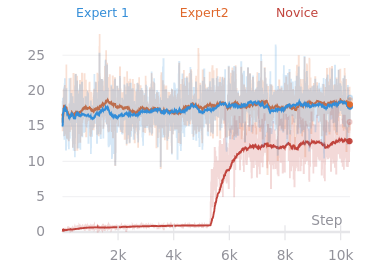
In cluttered environments, novice agents did not learn more effectively in the presence of experts. The chart below shows the average episode returns for solitary novices and novices learning with two experts. Each curve is the average of five trials, with the highlighted regions showing two standard errors.
Goal cycle, hidden goals
The videos above show the behavior of a novice agent learning in a goal cycle environment in the presence of experts. The two experts were trained together with a penalty curriculum. The novice agent’s partial views are shown below the two experts’ in the columns on the right. The experts are able to see the goals as usual, but the goals are masked out of the novice’s partial view. In this scenario, the novice agent develops a very robust following behavior. Since the novice agent is only able to follow the experts, it is unable to attain the level of expertise as the other experts. This mirrors a similar finding in Borsa et al. (2019), though in this case the experts as well as the novices are trained with RL.
Discussion
The purpose of this project is to find circumstances in which social learning occurs between independent agents. In scenarios conductive to social learning, novices can learn to accomplish a task more effectively in the presence of experts than they would alone. The motivating example illustrated in the introduction shows an extreme case in which novice agents in the presence of experts are able to attain high skill levels, but solitary novices are unable to (or extremely unlikely to).
When the exploration task is easy to solve directly (without incorporating information from other agents), the presence of experts confers no benefit to novices. This is the case in the cluttered environment, as shown above. Conversely when the behavior of other agents provides helpful cues for solving tasks, novices can learn policies that make use of that information, as I observed in the goal cycle environment with hidden goals.
Next steps
With three-goal goal cycle environments, it is difficult to construct a scenario in which solitary agents consistently fail to learn while novices robustly succeed at learning in the presence of experts. This is because novice agents (whether or not they are solitary) learn to avoid the penalty cost of exploration by avoiding goal tiles altogether (after receiving an initial reward), as shown below.
With more than three goals the penalty can be set such that there many non-expert strategies that still involve traversing goal tiles. I hypothesize that agents with such sub-optimal strategies would be more likely to learn to associate cues from experts with higher rewards, and thus might be more likely to learn social behavior. Discovering the correct cycle in environments with four or more goals is significantly harder, so training optimal experts poses a challenge. Still, I think this is a very promising direction.
In this post, I have used returns as a stand-in for skill. But agents that achieve high rewards by following experts might be following much simpler policies (i.e. “follow a blue agent”) than those that solve the task directly (i.e. “find one goal, then another; if the second gave a penalty, …”). One way to tighten up the analogy with human social skill acquisition would be to evaluate the transfer performance of trained novices in solitary environments.
References
Joseph Henrich (2015). The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter.
Michael Tomasello (2009). Why We Cooperate.
Diana Borsa et al. (2019) Observational Learning by Reinforcement Learning. AAAMAS 2019, Montreal, Canada, 2019.
John Schulman et al. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347, 2017.
Prafulla Dhariwal et al. baslines. GitHub repository https://github.com/openai/baselines. 2017.
The LSTM hidden state is actually comprised of “hidden” and “cell” values and would conventionally be expressed as a tensor of shape $[2\times n_h]$. I glossed over this distinction in the discussion above for the sake of brevity. ↩